Image understanding has been part of AI stacks for years. But the expectations have changed.
Images are no longer just content to be indexed or searched. They are inputs into systems that decide, trigger actions, and coordinate workflows. As AI moves toward agentic behavior, the limitations of traditional image tagging become increasingly visible.
Imagga’s Structured Image Tagging is designed for this shift.
The Core Problem: Images Are Still Treated as “Hints”
Most image tagging systems today behave like suggestion engines. They return a list of tags such as: person, street, city, walking, casual, urban, fashion, outdoors
This output might look useful at first glance, but it raises immediate questions for any system trying to act on it:
- Is person the primary object or just one of many?
- Is street the scene or just an object?
- Is urban an environment, a style, or a mood?
- Which of these tags should trigger a rule or workflow?
Humans can intuitively resolve this ambiguity. Software cannot-at least not reliably.
As long as images were consumed mainly by people, this was acceptable. Once images become inputs into automation pipelines, search ranking logic, or AI agents, ambiguity turns into friction.
From Tag Clouds to Structured Visual Semantics
Structured Image Tagging addresses this by changing the representation, not just the model.
Instead of returning a flat list of labels, Imagga organizes visual understanding into explicit semantic groups. Each tag has a role and a scope.
For example, a photo of a person walking through a city street might be structured as:
- Objects: person, sidewalk, buildings
- Scene: urban street
- Mood: casual, neutral
- Extended attributes: daytime, lifestyle
- Colors: gray, blue, beige
This structure immediately answers questions that flat tags cannot:
- What entities exist in the image?
- What is the overall context?
- Which attributes describe the scene versus the subject?
The image stops being a loose collection of hints and becomes a set of visual facts.
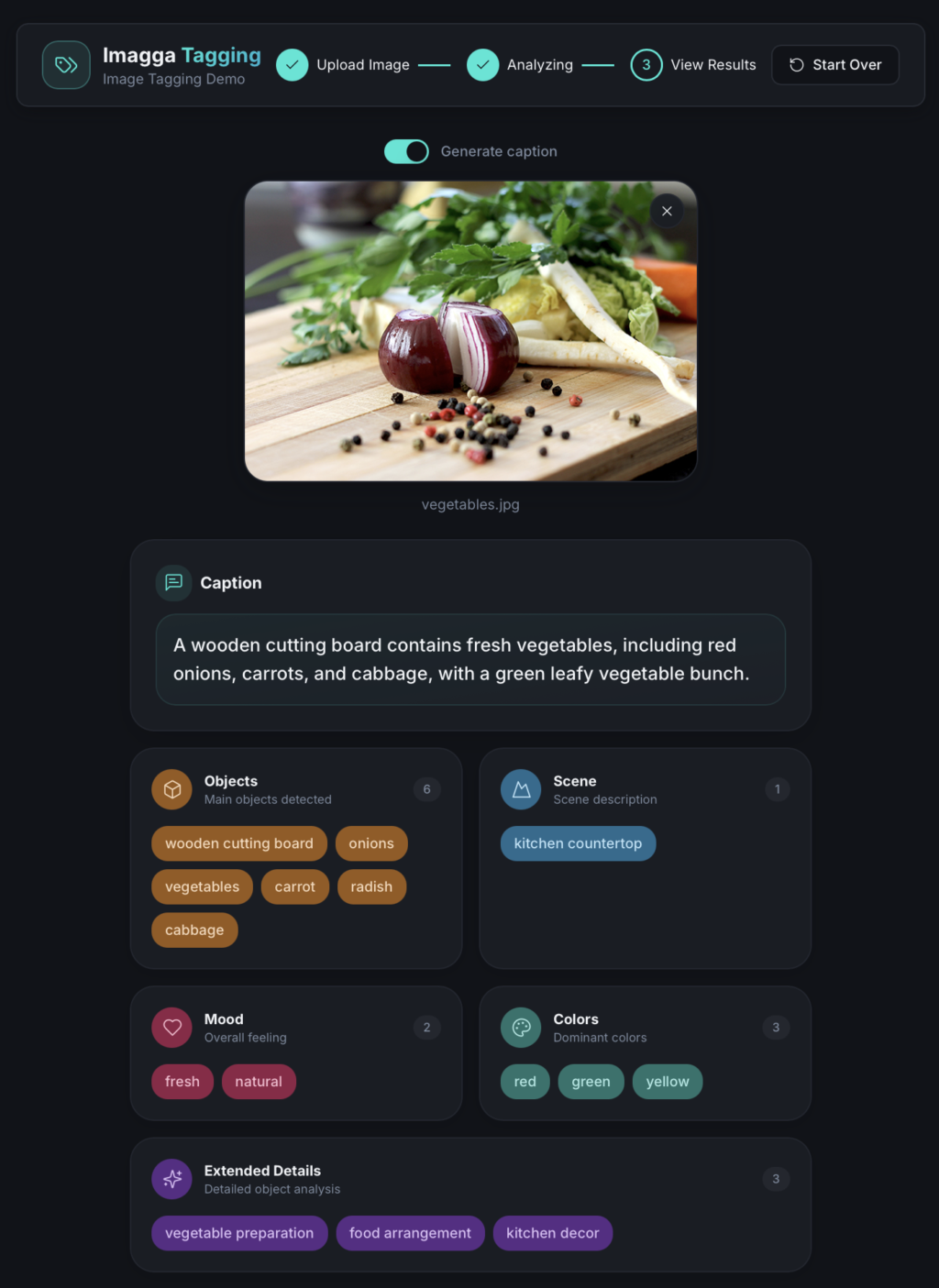
Try out our Image Tagging Demo
Why This Matters for Agentic AI
Agentic AI systems do more than predict outcomes. They plan, decide, and act.
To do this, they rely on inputs that are:
- Deterministic
- Predictable
- Easy to combine with rules and policies
Flat tag lists force downstream systems to guess intent, tune thresholds, or apply brittle heuristics. Structured Image Tagging removes that burden.
Example: Rule-Based Automation
Imagine an automation system that needs to route images differently based on context:
- Product photos go to an e-commerce enrichment pipeline
- Lifestyle photos go to marketing
- Images with people go through a privacy review
With flat tags, this requires confidence thresholds and custom logic. With structured tags, the logic becomes straightforward:
- If Objects include person → trigger review
- If Scene is studio → treat as product image
- If Scene is outdoor and Mood is lifestyle → route to marketing
The structure enables clear, explainable decisions.
Precision Over Recall (By Design)
It’s important to note that Structured Image Tagging is not meant to replace probabilistic auto-tagging.
High-recall tagging remains valuable for discovery use cases like broad search or recommendation. Imagga continues to support this through its existing Auto-Tagging API.
Structured Image Tagging focuses on a different goal:
- Precision
- Semantic clarity
- Downstream usability
This makes it especially suitable for systems where false positives are costly or where outputs feed directly into automated decisions.
Captions as a Deterministic View
Captions are often treated as the “understanding” of an image. In reality, they are usually another probabilistic output.
Structured Image Tagging flips this relationship.
Here, captions are derived, not guessed. They are generated as a deterministic rendering of the structured tags. No new concepts are introduced. No speculation is added.
This has practical implications:
- Humans get readable summaries
- AI systems rely on structured data
- Captions remain explainable and auditable
The structured tags stay the source of truth. Captions are simply a presentation layer.
Built for Production Systems
From an engineering perspective, Structured Image Tagging is designed to integrate cleanly into real-world systems.
- Stable, versioned response schema
- Clear semantic boundaries
- No need for post-processing or threshold tuning
- Compatible with existing Imagga authentication and image input methods
Two model variants-light and pro-allow teams to balance speed, cost, and semantic depth depending on their workload.
This makes it practical not just for experimentation, but for long-term production use.
Practical Use Cases
Structured Image Tagging is especially relevant for teams building:
- Agentic AI systems that reason over visual inputs
- Visual-based automation and workflow engines
- Search and filtering interfaces with strict semantics
- E-commerce enrichment pipelines
- Compliance, moderation, and review systems
- Multimodal AI combining text, images, and rules
In all these cases, the key requirement is the same: visual data must be reliable enough to act on.
A Shift Toward AI-Native Image Understanding
As AI systems become more autonomous, image understanding must evolve accordingly.
The future is not about generating more tags. It’s about generating clear, structured visual knowledge that machines can reason over without ambiguity.
Structured Image Tagging represents that shift-and positions Imagga at the intersection of computer vision and agentic AI.
For teams building systems that need more than surface-level image annotations, this approach provides a foundation designed for how AI actually works today-and where it’s headed next.
To learn how to use Imagga’s sturctured image tagging, use our Imagga API Reference.