Text-in-image moderation is the process of detecting and managing harmful or sensitive words that appear inside images — in memes, screenshots, user-uploaded photos, or even video frames. It ensures that the same safety standards applied to captions, comments, and posts also apply to words that are visually embedded in pictures.
For platforms that rely on user-generated content, this capability closes a significant gap in content moderation. Without it, harmful text often slips through unnoticed, undermining safety measures and leaving communities vulnerable.
Why Text-in-Image Moderation Has Become Essential
In today’s internet, content rarely appears in one neat format. Users mix images and text in increasingly creative ways. A joke or insult is shared through a meme; a screenshot of a conversation circulates widely; a product photo includes hidden comments on the packaging.

Each of these cases can carry risks:
- Memes are powerful carriers of hate speech, harassment, or misinformation.
- Screenshots often reveal personal data, private conversations, or defamatory text.
- Background text in everyday photos (posters, graffiti, signage) may introduce inappropriate or harmful content.
- In-game images or livestreams may expose offensive usernames or chat logs.
These risks are not hypothetical. In fact, embedding harmful text inside visuals is one of the most common ways malicious users evade filters. If a platform only scans written text, like captions or comments, offensive or dangerous content inside images goes completely unchecked.
The takeaway is simple: text-in-image moderation is no longer optional. It has become essential for platforms that want to maintain safe, trustworthy environments for users and advertisers alike.
Where Text-in-image Moderation Fits in the Content Moderation Ecosystem
Text-in-image moderation sits at the crossroads of text, image and video moderation. It deals with language, but in a visual format. By bridging this gap, it completes the “visual content safety picture.”
To see why text-in-image moderation matters, it helps to place it within the larger system of content moderation:
- Text moderation looks at written language in posts, captions, and comments.
- Audio moderation automatically detects, filters or flags harmful content in spoken audio, such as hate speech, harassment, or misinformation.
- Image moderation analyzes visuals to flag nudity, violence, or other explicit content.
- Video moderation examines both frames and audio to identify unsafe material.
Imagine a platform that catches explicit images and bans offensive captions, but allows a meme carrying hate speech in big bold letters. Without text-in-image moderation, the system is incomplete. With it, platforms can finally ensure that all forms of content — written, visual, or hybrid are subject to the same safeguards.
The Biggest Challenges of Moderating Text Inside Images
On paper, moderating text inside images sounds simple: just read the words with software and filter them like any other text. In practice, the task is far more complex. Five challenges stand out:
Context matters
Words cannot be judged in isolation. A racial slur on a protest sign means something very different from the same word in a news article screenshot. Moderation systems need to understand not just the text, but how it interacts with the image.
Poor quality visuals
Users don’t make it easy. Fonts are tiny, distorted, or deliberately stylized. Text may be hidden in a corner or blurred into the background. Even advanced systems struggle when the letters are hard to distinguish.
Language diversity
Harmful content isn’t limited to English. It appears in multiple languages, code-switching between scripts, or encoded through slang and emojis. A robust system needs to keep up not just with dictionary words, but with the constantly evolving language of the internet.
Scale
Billions of memes, screenshots, and photos are uploaded every day. Human moderators can’t possibly keep up. Automation is required, but automation must be accurate to avoid flooding teams with false positives.
Evasion tactics
Malicious users are inventive. They adapt quickly, using creative spellings, symbols, or image filters to disguise harmful text. Moderation systems must evolve constantly to stay ahead.
These hurdles explain why text-in-image moderation is still an emerging capability. They also highlight why relying on traditional methods like scanning captions alone is no longer enough.
Emerging Solutions for Text-in-Image Moderation
Despite the challenges, new technologies are making text-in-image moderation increasingly effective. Most solutions use a layered approach:
Optical Character Recognition (OCR)
OCR is the classic technology for extracting text from images. It converts pixels into characters and words. For clear, standard fonts, OCR works well. But when text is distorted, blurred, or stylized, OCR often fails.
AI-powered Vision-Language Models
The recent wave of Vision-Language Models (VLMs) has changed the game. These models can interpret both the image and the embedded text, understanding them in combination. For example, they can recognize that a phrase in a meme is meant as harassment or that a number sequence in a screenshot may be a credit card.
Hybrid Approaches
The strongest systems combine OCR with fine-tuned vision-language models. OCR handles straightforward cases efficiently, while the AI model interprets context and handles more difficult scenarios. This hybrid method significantly reduces blind spots.
Human + AI Workflows
Automation handles the majority of cases, but edge cases inevitably arise. Escalating ambiguous content to trained reviewers ensures that platforms avoid over-blocking while still protecting users from real harm.
Together, these approaches form the foundation of modern text-in-image moderation systems.
How Imagga Approaches Text-in-Image Moderation
Imagga has long been recognized for its state-of-the-art adult content detection in images and short-form video. Building on that foundation, the company now offers text-in-image moderation as a way to complete its visual content safety solution.
Imagga’s system:
- Combines advanced OCR with a fine-tuned Visual Large Language Model.
- Detects even very small or hidden text elements inside images.
- Flags sensitive categories such as hate speech, adult content references, or personally identifiable information (PII).
- Allows clients to adapt categories — excluding irrelevant ones or adding new ones based on platform-specific needs.
This adaptability matters. A dating app, for example, may prioritize filtering out sexual content and PII, while a marketplace may focus more on hate speech and fraud prevention. Imagga’s approach ensures each platform can tailor the system to its own community standards.
For a detailed look at how the technology works in practice, see How Imagga Detects Harmful Text Hidden in Images.
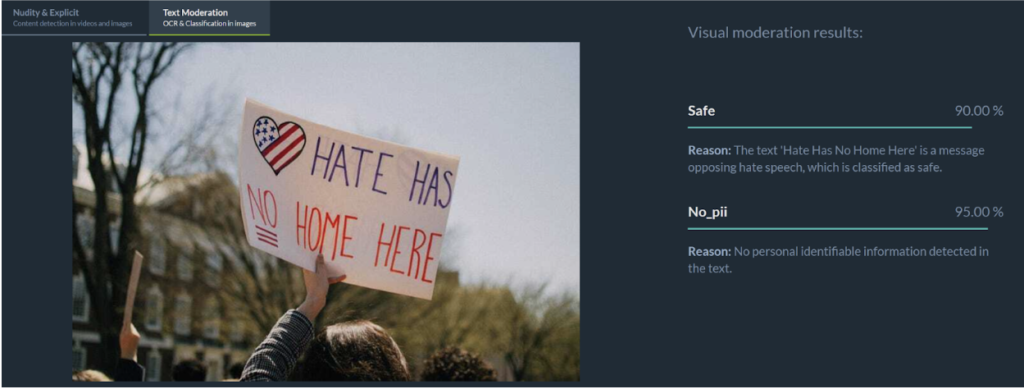
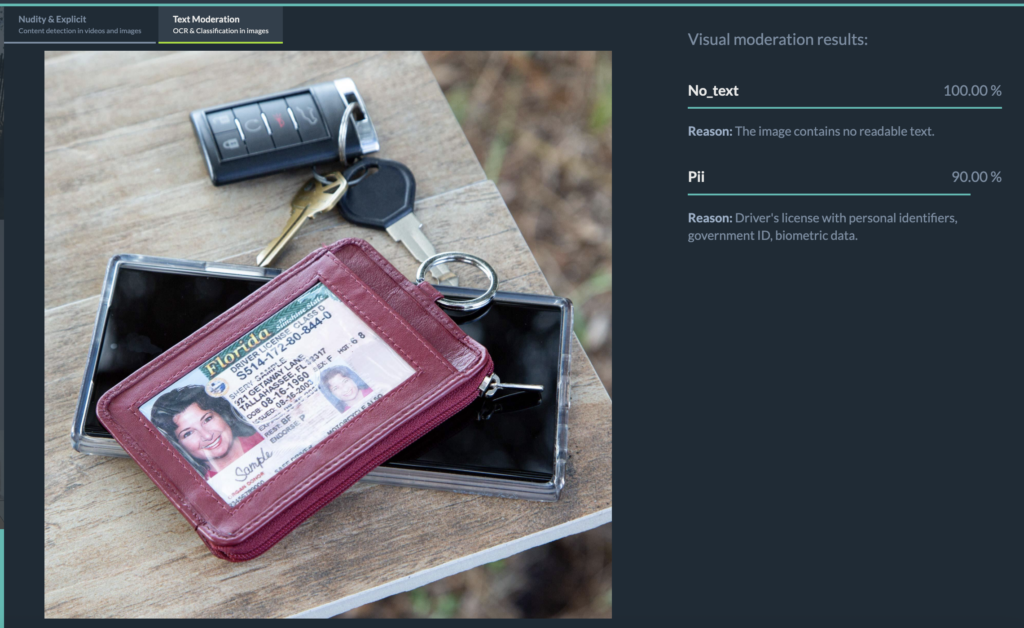
The Future of Text-in-Image Moderation
The demand for text-in-image moderation is only going to increase. Several trends are pushing it to the forefront:
- Regulation – Laws like the EU’s Digital Services Act require platforms to take proactive measures against harmful content. Ignoring text-in-image would leave an obvious gap. Read our blog post on “What the DSA and AI Act Mean for Content Moderation”
- Advertiser pressure – Brands don’t want their campaigns displayed next to harmful memes or screenshots. Content safety is directly tied to ad revenue.
- User expectations – Communities thrive when users feel protected from harassment and harm. Platforms that fail to act risk losing trust.
As the internet becomes ever more visual — with memes, short-form video, and livestreams dominating feeds — moderation systems need to cover every corner. Platforms that adopt text-in-image moderation today will be ahead of the curve in compliance, user trust, and advertiser confidence.
Stats That Highlight the Need for Text-in-Image Moderation
- About 75% of people aged 13–36 share memes (Arma and Elma)
- On Reddit, meme communities are enormous – the r/memes subreddit alone has over 35 million subscribers (among the top 10 subreddits on the site) Exploding Topics
- Platforms report that a substantial portion of hate speech violations occur via images or videos, not just plain text (The Verge)
- These “hateful memes” often combine slurs or dehumanizing imagery with humor or pop culture references, making the hate content less obvious at first glance (Oversight Board)
These figures underscore why embedded text can’t be ignored — it’s one of the most common, and most dangerous, blind spots in moderation.
Final Thoughts
Text-in-image moderation may once have seemed like a niche problem. Today, it is central to keeping digital communities safe. Words hidden in memes, screenshots, or product images are just as harmful as offensive captions or explicit visuals. Platforms that fail to detect them leave users exposed and advertisers uneasy.
The good news is that technology is catching up. Hybrid systems that combine OCR with AI-driven vision-language models are capable of extracting and interpreting text even in complex contexts. Companies like Imagga are already applying these advances to deliver adaptable, accurate solutions that fit the needs of different platforms.
FAQ: Text-in-Image Moderation
What is text-in-image moderation?
Text-in-image moderation is the process of detecting and filtering harmful or sensitive words embedded inside images, such as memes, screenshots, or video frames, to ensure platforms apply the same safety standards to visual text as they do to captions and comments.
Why is text-in-image moderation important?
Without it, harmful content hidden in memes or screenshots slips past filters, exposing communities to harassment, hate speech, and misinformation. It closes a critical gap in content moderation.
How does text-in-image moderation work?
Most systems combine Optical Character Recognition (OCR) to extract text with AI vision-language models that interpret context, tone, and intent. Hybrid human + AI workflows handle edge cases.
What challenges make text-in-image moderation difficult?
Key challenges include poor image quality, diverse languages and slang, evolving evasion tactics, and the massive scale of user-generated content. Context also matters — the same word may be harmful in one setting but harmless in another.
Which platforms benefit most from text-in-image moderation?
Any platform with user-generated content — social media apps, dating platforms, marketplaces, gaming communities, or livestreaming services — gains stronger safety, advertiser trust, and compliance with regulations like the EU Digital Services Act.
How is Imagga different in its approach to text-in-image moderation?
Imagga combines advanced OCR with fine-tuned vision-language AI to detect even small or hidden text. Its adaptable categories let platforms focus on the risks most relevant to their communities, from hate speech to bullying and personal data exposure.
This publication was created with the financial support of the European Union – NextGenerationEU. All responsibility for the document’s content rests with Imagga Technologies OOD. Under no circumstances can it be assumed that this document reflects the official opinion of the European Union and the Bulgarian Ministry of Innovation and Growth.