Enable Product Search by Image in Your Platform
In an increasingly visual-first digital world, users don’t want to describe…

Imagga’s Adult Video Content Detection Model: Smarter Moderation, Safer Platforms
Video is everywhere today — from social feeds and online communities to…

How Smart Video Moderation Boosts Platform Trust
A 2025 global survey conducted by the University of Oxford and the Technical…

Image Moderation - Meaning, Benefits and Applications
Image moderation has become indispensable for keeping our digital environments…

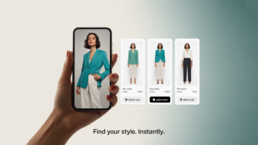
Virtual Try-On Fashion: Transforms the Shopping Experience
Technology is stepping in to revolutionize most aspects of our lives, and the…

From E-Learning to Shopping: The Overlooked Need for Adult Content Detection
Content moderation has become a necessity in our online lives, providing…

From Illegal to Harmful: What the DSA & AI Act Mean for Content Moderation
Two key pieces of legislation, the Digital Services Act or DSA and the…

What is Image Recognition? Technology, Applications, and Benefits
Listen to a concise summary of the article What if technology could…

Types of Content Moderation: Benefits, Challenges, and Use Cases
Content moderation is the practice of monitoring and regulating user-generated…

What is Video Moderation And Why Digital Platforms Need It
In 2023, the average person spent 17 hours per week watching online video…