
Imagga Named As One of the IDC 2016 Worldwide Image Analytics Innovators
Imagga is recognized as one of the 3 pioneering players in the worldwide image analytics market. IDC’s 2016 Innovators report acknowledges companies that offer an inventive technology and/or groundbreaking new business model.
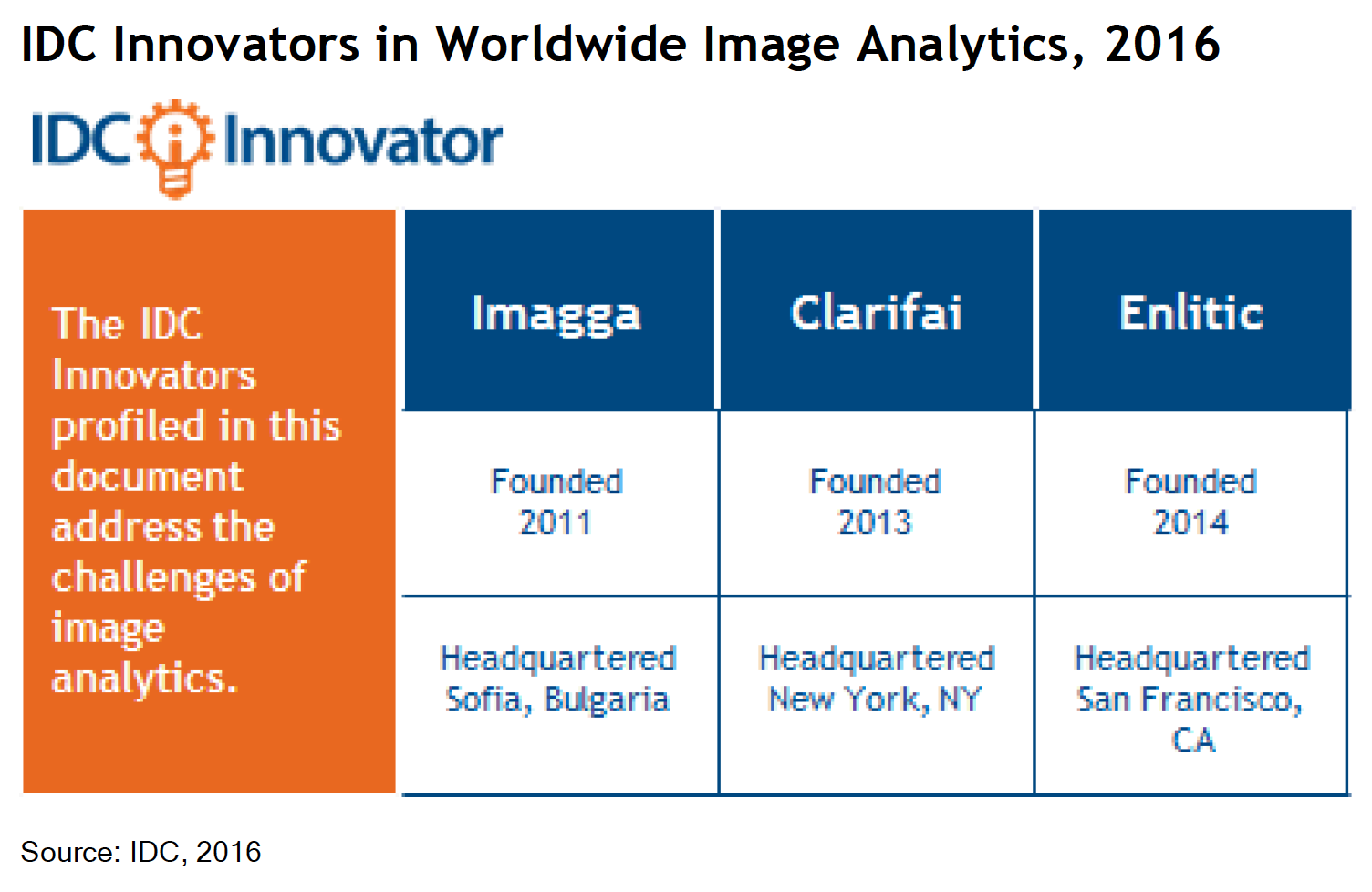
Imagga stands out with the possibility to offer custom image recognition training using custom-provided data for training sets, according to the prestigious report. Thanks to the flexible training model, customers are offered unprecedented opportunity to make sense of their image content and use the insights for analytics, understanding customers or better monetization strategies. Depending on the complexity of the training model, it takes form a day to couple of days for the actual training. Customers are given visual tools to evaluate the results and decide if fine-tinning is needed for greater performance.
According to Carrie Solinger, senior research analyst at Cognitive Systems and Content Analytics “Application of natural language processing and machine learning technologies have advanced image analytics’ cost effectiveness and accuracy, exponentially”. Services as Imagga enable business to harness the power of machine learning and do what once was done manually with great expense of manpower, or was impossible due to time restrictions. Real time (or near real time) image analytics opens up totally new horizon for companies to optimize their business decisions with direct effect on productivity and business results.
You can download this report from IDC here.


Moderating adult content, our new NSFW categorizer
The internet provides amazing opportunity to connect with each other and share information. But like every great invention, it has a dark side. Explicit content is lurking around every corner and it’s not uncommon to stumble upon it while innocently browsing the web. We call that content Not Safe For Work (NSFW) - not safe for minors and unappropriate for work.

We have been working hard to offer an excellent solution for detecting adult content and providing extremely effective API for distinguish between photos that are safe for work (no nudity), semi-safe (underwear and swimwear) and totally safe (no nudity whatsoever).
The NSFW (not safe for work) categorizer can be of extreme help for almost any online business that deals with user generated photos, or aggregates such from third parties. Various countries have quite strict restrictions on what content can be publicly available to minors, so we can help them too comply with the requirements. Not to mention Apple’s App Store restrictive rules on nudity that have been observed severely and have caused problems for apps, especially in the dating vertical.
Up to now, user generated photo content has been moderated manually. This is a time consuming and expensive process. It also, has some privacy problems - your sensitive content might end up being checked by somebody that you personally know (quite embarrassing, the world is small and this happens more often than you think).
Our adult content moderation categorizer can automate this process, so you can get a lot more content done in no time. The technology is in beta stage, and there might be some flaws, but we are still able to cover you and your app!
Currently our NSFW (adult content image moderation) categoriser puts images in three categories:
- nsfw - not safe at all - expect p0rn images, nudes, body parts to be put into this category.
- underwear - medium safe images such as lingerie, underwear, pants
- safe - completely safe images without nudity

Here are a couple of uses cases that illustrate how our NSFW Categorizer can be used to speed up the process of content moderation:
Marketplaces - awesome for online shops/marketplaces where people upload products (along with some photos) and you provide the infrastructure. The NSFW filter can be moderately restrictive - underwear and swimwear photos can be included, but only nude photos stay out of the public pages.
Kids websites/communities - perfect candidate for aggressive filtering of adult content. Anything related to nudity can be filtered out. Imagga’s NSFW categorizer can be the first step of automated elimination of problematic adult content and then the rest can be manually moderated to make sure unapropriate photos are out of kids’ sight.
Dating websites - there are lots of issues here with adult content, especially when it comes to apps for iPhone. Dating sites employ lots of people to eliminate the problem. Sometimes you need to upload a new profile photo to impress somebody special and it’s very frustrating when moderation takes forever even though you uploaded just a facial photo.
There are probably tons of cases where the NSFW categorizer can be of very practical use. Why don’t you give it a try and share your impressions?

2015 Recap: Growth
2015 is over and it’s time to do a recap of the year and remember the good and the bad. It was a joyful and at the same time a challenging year, but there is one word that resonates in everyone from the Imagga family - GROWTH.
#1 Self-service Cloud API Growth

It’s been amazing to see our self-service cloud API customer base grow significantly. Lots of exciting practical applications were developed using Imagga API, but we also saw some really cool and funny apps developed with our tagging technology - application that recognizes hipsters and only lets them into a bar, automated sorting of hotel images, powerful user profiling to empower smart car selection process and many, many more.
#2 Big Enterprise Customers in US, EU and Asia

It’s a different sales channel but the same amazing image recognition technology that helped our enterprise clients better serve their customers. Can’t be more grateful for the trust and the opportunity to work and learn together.
#3 Great Image Recognition Technology Advancement

We worked hard to make the automated image tagging technology more precise and reliable - now we can recognize more objects and concepts and are quite good at it. Scaling up the API to virtually any load that needs to be handled was a major milestone to make sure we can meet our enterprise customers’ demands. Video tagging is in beta and we are excited to mature it with the help of couple of committed customers in the upcoming months. Offering custom training for automated image categorization was another major milestone that we nailed in 2015. Recently we added the first versions of our multi-language support.
#4 Team & Advisors

We’ve put lots of efforts into building up the AI knowledge and motivation of the team. It’s been awesome to add the first female member and we'll definitely grow that number next year. Team building retreat in the mountains and playing bowling regularly was great fun. LAUNCHub, our current investor and Vassil Terziev, angel investor and founder of Telerik were vivid supporters and precious advisors on product and business strategy decisions.
#5 Events, Hackathons, Startup Competitions

Being part of the startup community locally in Sofia, as part of the greater European startup family, is awesome experience. This summer we started Machine Learning meetups in Sofia and plan to grow the event in the next year. We’ve also supported multiple hackathons by providing cool prizes and access to the Imagga image recognition API.
We exhibited at the NVIDIA's GPU Tech conference in April and met lots of partners and customers there. We are selected to present in the 2016 edition of the same conference in April and will be happy to meet there and tell you about the exciting business applications of machine learning for image recognition and some of the technical challenges we've solved along the way.
Winning South Summit’s award for best startup in the Technology for Big Players category in October was a great recognition for us. Our CEO Georgi had the honour to get the award personally from HM Felipe VI, King of Spain.
Imagga has also been selected as one of the winners of the Balkan Venture Forum in Belgrade, Serbia & The World Summit Award by UN.
In the beginning of December we were selected as one of the 7 companies to take part into inaugural growth program of Google Campus Warsaw - valuable experience with lots of new contacts from the European VC and startup community.
#6 Partnerships & Networking

Big part of our strategy to spread the word about the awesome image recognition technology we’ve developed and make it even more accessible to developers all over the world is through partnerships. We’ve added three more during 2015 - Automatic image categorization and tagging with Imagga, AYLIEN and OntoText S4 and are quite excited to help them serve better their clients by adding advanced image categorization and tagging to the range of services they offer.
We’ve also become part of EIT ICT Future Cloud family of companies and this opens up lots of new opportunities for business development in Europe and the US.
#7 Break-even

Somebody has said that the best investors in your company are actually your customers. It’s amazing to see so many developers, businesses and enterprises trust Imagga’s API and use it to do things unimaginable before. They help us to reach break-even and continue to grow the company organically.
We are ready to jump into 2016 with lots of things in the pipeline:
- Major update of the technology – in terms of both precision and capabilities. Stay tuned!
- Improvements of our web platform, including our API documentation, tutorials and onboarding tools
- Discovering new verticals and helping even more developers and business to make great use of our image recognition API.
If you haven’t tried our APIs yet, make sure to sign up for Imagga
Imagga @ Machine Learning Event at SAP Labs Bulgaria

Machine learning is getting lots of attention lately. It’s amazing that some 200 people showed up at Hack Bulgaria event and stayed almost 3 hours to learn more about machine learning. Not to mention it was friday and the venue was not in the center of the city! It was a clear indication for us that lots of developers are getting curious about machine learning (ML) and that’s totally cool for companies like ours.
This is a short overview of our not so tech presentation about machine learning for images. Some of the other lecturers have covered different aspects of ML and it’s application in various cases and industries.
From the moment of their invention the convolution networks were great for tasks as face detection and handwriting. Thanks to the advance of the GPU technology and the extended base of image data, the convolutional networks demonstrated far better results for complicated tasks such as visual classification of objects in images.
There are some specifics when it comes to image recognition using machine learning. Images are a matrix of pixels (raster data) and that’s why recognition is sensitive to lighting, contrast, saturation, blur, noise, geometric transformations (scaling, translation, rotation) and occlusion.

Conventional image recognition methods struggle to find the optimal set of filters (convolutions) to apply for each specific use-case.
There are multiple levels and scales of interest, from low-level features such as texture to high-level features such as composition. On the top of that there’s a need for data-augmentation to compensate for sensitivity (e.g. training with blurred, cropped, scaled, noised versions of the images)
In order to do proper image analysis you will need huge (both deep and wide) architecture which requires massive amount of memory and processing power, made more accessible today via GPU empowered machines. It still takes a lot of time (up to 10 days) to train some large architectures.
There are a few implementations for convolutional neural networks.
- cuda-convnet - python interface, c++/cuda implementation for convolutional neural networks, training using back-propagation method, fermi-generation nVidia GPU(GTX 4xx, GTX 5xx, or Tesla equivalent) is required, but no multi-GPU support
- cuda-convnet2 - an upgrade to cuda-convnet, optimized for new kepler-generation nvidia gpus and added multi-gpu support
- caffe - deep learning framework, developed by Berkeley Vision and Learning Center, big community of contributors, support for nVidia’s GPU accelerated convnet library - cudnn
- torch7 - lua interface, with support for python, wide support for machine learning algorithms, one of the fastest implementation for convnet is a torch7 extension - fbcnn from facebook artificial intelligence research team; there are other extensions as well and a support for cudnn
- theano - a python library, open-ended in terms of network architecture and transfer functions, slightly lower-level than the other implementations
We will be doing a series of articles in our blog on how image recognition is changing the paradigm and will allow image intensive business to finally better understand and monetize their image contents.
[slideshare id=47160420&doc=imaggaproductpresentationmleventslideshare-150419060621-conversion-gate02]

Machine Learning Meetup in Sofia
Three year ago when we publicly talked about machine learning, deep learning, convolutional neural networks and AI not many people were getting it. It was hard to explain what all this is about. Things have changed, and for good.
Last week we’ve invited a bunch of people to Machine Learning meetup. The first in Sofia. 60 people attended and it was awesome. It’s awesome to see so many people interested in AI and machine learning. And they were getting it. We are sure machine learning will be widely adopted in many tech verticals in an year or so and are proud to be helping Bulgarian AI/ML community to exchange ideas and grow.
Judging by the number of people and cases that has been discussed, lots of startups are already exploring the power of machine learning in various industries - e-commerce, bitcoin landing, real estate, to mention few. It’s still the early days of ML community in Sofia, so we’ve started with some basics. Judging by the variety of the questions after our short intro presentation, next editions of Sofia Machine Learning Meetup will be quite geeky and interesting.

Some More Image Recognition Tests, Some More Great Results
Yesterday we tested Imagga’s deep learning algorithms against 6 others. The results were quite good and we believe our tech is doing an amazing job recognizing everyday objects with impressive accuracy.
Looks like there’s another interesting test of various image recognition technologies, this time performed by Jack Clark for Bloomberg Business with several challenging images.
It’s quite fascinating to run the same images, the author has originally used, via the Imagga image tagging demo to find out how we perform as well. Imagga tech definitely thinks Mark Zuckerberg is more than a cardigan, but still tags him with а few trivial words (see the results below). May be the subtitle of the article would be different if Imagga’s image tagging was considered, but the ‘Best answer’ section would be a bit boring ;)
Let’s have some fun now (feel free to use Imagga auto-tagging demo to test with your own images):
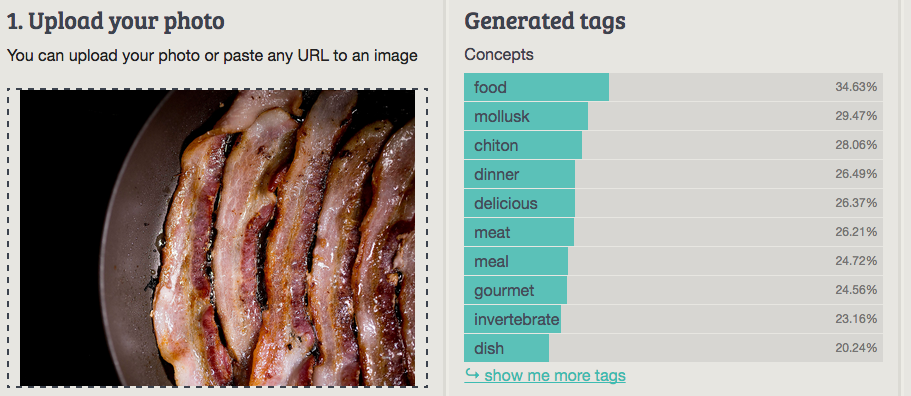
Imagga: food
Best answer: Fat (Clarifai)
Worst answer: Slug/Churros (MetaMind, demo version)
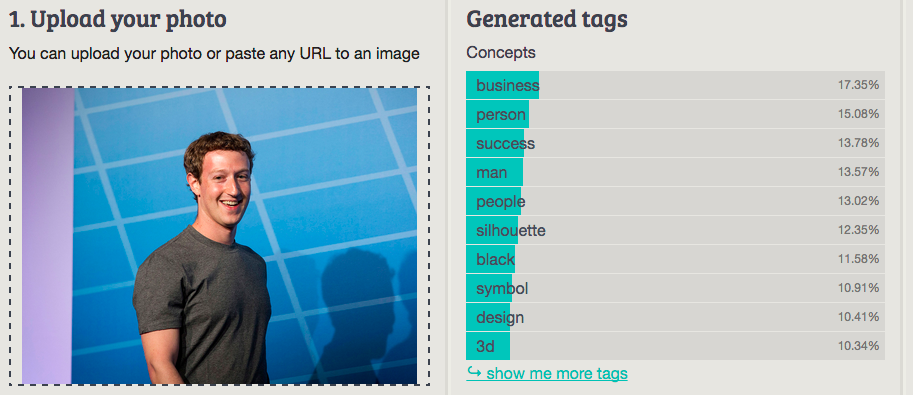
Imagga: business
Best answer: Cloth/Zuckerberg (Orbeus)
Worst answer: Cardigan (MetaMind, demo version)
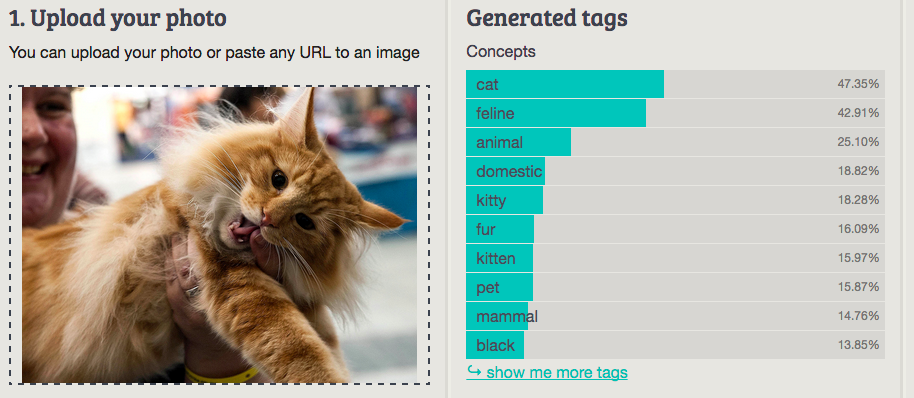
Imagga: cat
Best answer: Cat—everyone got this. After all, the Internet is made of cats.
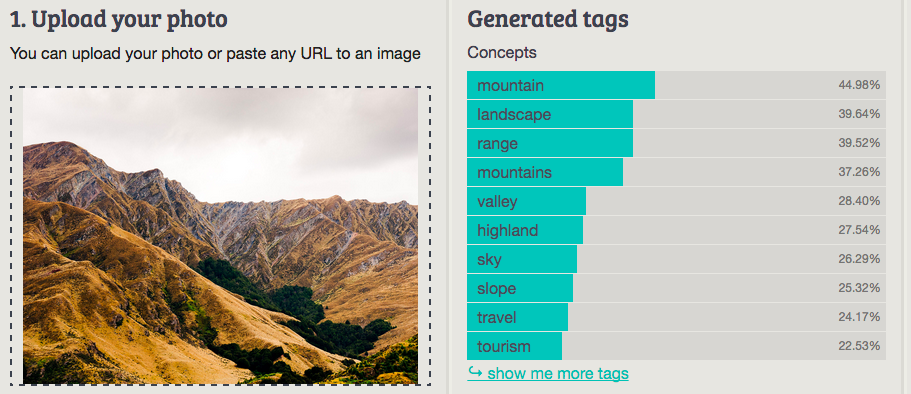
Imagga: mountain
Best answer: Mountain (Orbeus)
Worst answer: Vehicle/Scene (IBM Watson Visual Recognition, beta version)
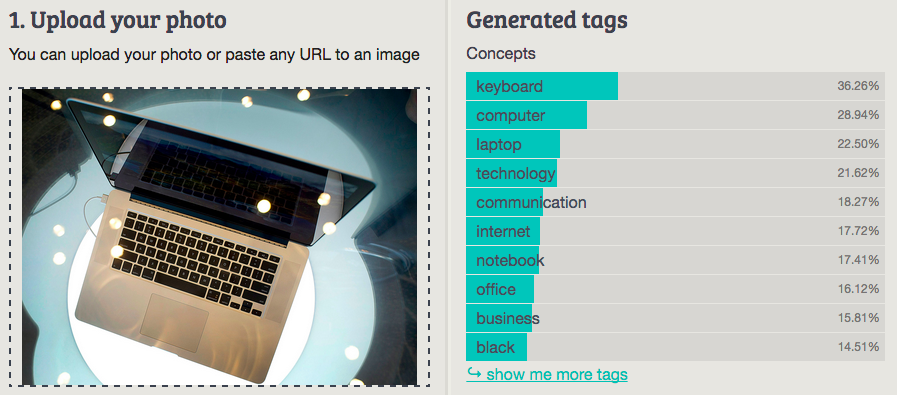
Imagga: keyboard
Best answer: Technology (Clarifai)
Worst answer: Photo/Object (IBM Watson Visual Recognition, beta version)
Have an amazing idea but felt sceptical about image recognition? Give Imagga's super easy to use API a try and you'll change your mind :)

Imagga among the 40 winners of UN-based World Summit Award 2015
Imagga was selected as one of the winners of the World Summit Award, a global initiative in cooperation of the United Nations World Summit on the Information Society (WSIS) and UNESCO, UNIDO and UN GAID. WSA is the only ICT event worldwide, that reaches the mobile community in over 178 countries.
Imagga Image Recognition PaaS will be honored to receive the Award in e-Media & Journalism category in front of UN representatives, ICT ministries and the private sector at the World Summit Global Congress in Shenzhen, China, in February 2016.
“It’s extremely exciting to see two Bulgarian companies - Imagga (e-Media & Journalism category) and Bee Smart (e-Health and Environment category) as finalists of the World Summit Award 2015. Having two winning teams happens for the first time since Bulgaria participates in the prestigious award”, states Pavel Vurbanov, European Software Institute - Center Eastern Europe.
The 40 winners representing 24 countries were carefully selected from 386 nominations. The goal of the award is to showcase the world’s best practices in digital innovation - from Japan to Brazil and from Norway to Australia.
The WSA winners were selected by a jury of international ICT experts in two democratic rounds. Each UN Member State is eligible to nominate one product per category for the World Summit Award. This way any nomination results from a national pre-selection prior to the international WSA Jury.
Imagga at Hack The Visual
During the last couple years we’ve been taking part in numerous hackathons and events. Hack The Visual was perfect fit for what we do at Imagga. The goal of the event is to connect different types of visual data to each other and create new and interesting prospective. All data is welcomed - pictures, music, video, geo-data, even open data, you name it. In just 48 hours over 100 participants were hacking on projects mashing existing APIs and data sets to find a solution for a real life visual problem.
The main challenge was to bring together photos, videos and other kind of imagery with hardware, interfaces, platforms, apps & services in order to unlock the next step in visual culture.
Tree main tracks have been set based on research by Imaging Mind (organizer of the event) regarding the future of imaging:
- meshed capture - connecting multiple camera sources to generate new experiences. Winner: Camera Crowd - combining multiple photos and their location data with a photo of the area you are. A mesh of pictures from different sources blended into the space
- new perspectives/interpretation of images - accessing various image data sets to extract value from them outside of the image itself. Winner: Hear The Picture - by linking each coloured pixel to its individual sound, a photo could be ‘heard’ through its own distinctive soundtrack
- interactive visuals - reworking the static images into interactive new experience. Winner: Sharon - watch the same video source with multiple people, and allow synced manipulation of the video
Grand Prize went to Splatmap - web application that allows you to photograph buildings with your smartphone and plot the information into the application.

The special Imagga API prize went to Remember - app that triggers your memories using your own photo collection. Re/Visit a place and Remember will remind you of pictures you or someone else snapped nearby. It can also search for relevant photos based on the topics in the photo (using Imagga’s image recognition tagging API), turning your photo library into a smart conversation starter wherever you might be.
Overall, great event! See you next time. And do not forget to give Imagga APIs a try!
Imagga and 6 alternative image recognition services
In a recent post on the newly introduced component of Wolfram’s language for image identification ImageIdentify Jordan Novet of Venture Beat conducted a quick test of ImageIdentify against 5 deep learning platforms for image recognition he chose. He selected “10 images from Flickr that seemed to clearly fall into the 1,000 categories used for the 2014 ImageNet visual recognition competition.” and tagged them with ImageIdentify and 5 alternative image recognition services.
As one of the very first platforms as a service, offering such functionality worldwide, we felt we should join this funny experiment and make our humble contribution, by adding the tags Imagga’s image recognition technology generated for the same 10 photos. You can try with your own photos using Imagga online image recognition demo.
We better leave the results speak for themselves. Please take all this with a grain of salt and don’t forget that these results are obtained for just 10 randomly selected photos :)
1. Coffee Mug
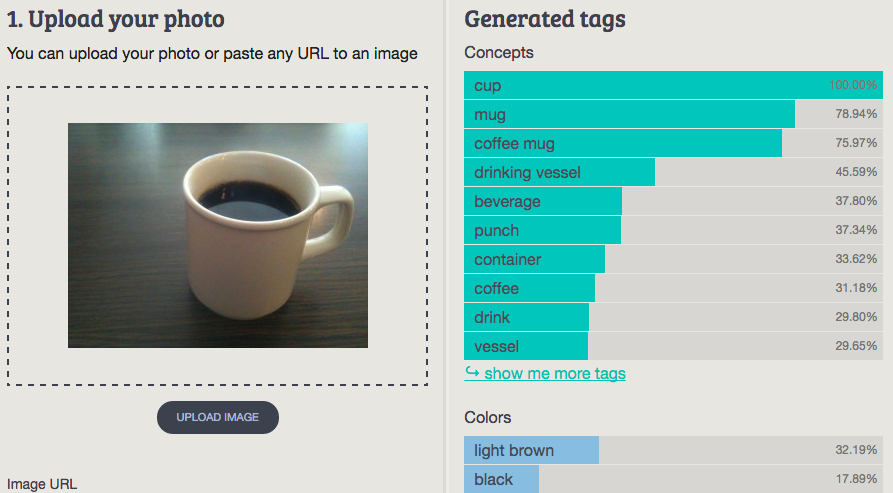
Imagga: cup, mug, coffee mug, drinking vessel, beverage, punch, container, coffee, drink, vessel
Wolfram ImageIdentify: tea
CamFind: white ceramic mug
Clarifai: coffee cup nobody tea mug cafe hot ceramic coffee cup cutout
MetaMind: Coffee mug
Orbeus: cup
AlchemyAPI: coffee
2. Mushroom
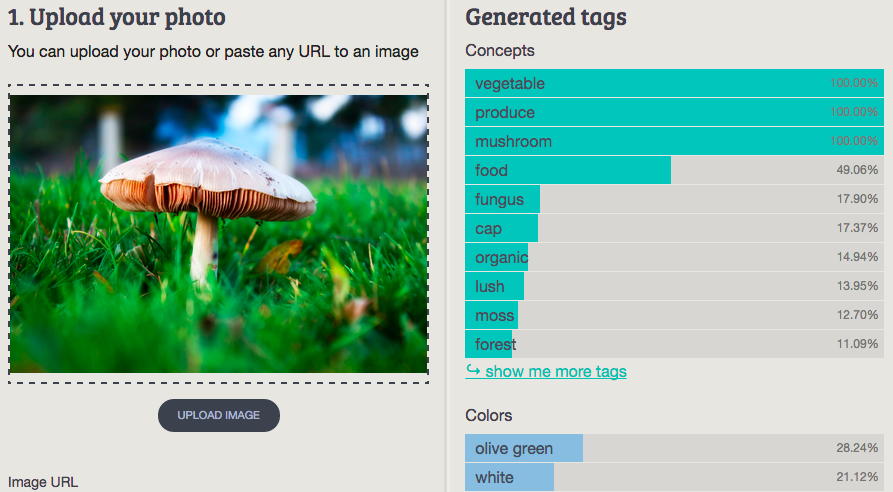
Imagga: vegetable, produce, mushroom, food, fungus, cap, organic, lush, moss, forest
Wolfram ImageIdentify: magic mushroom
CamFind: white mushroom
Clarifai: mushroom fungi fungus toadstool nature grass fall moss forest autumn
MetaMind: Mushroom
Orbeus: fungus
AlchemyAPI: mushroom
3. Spatula
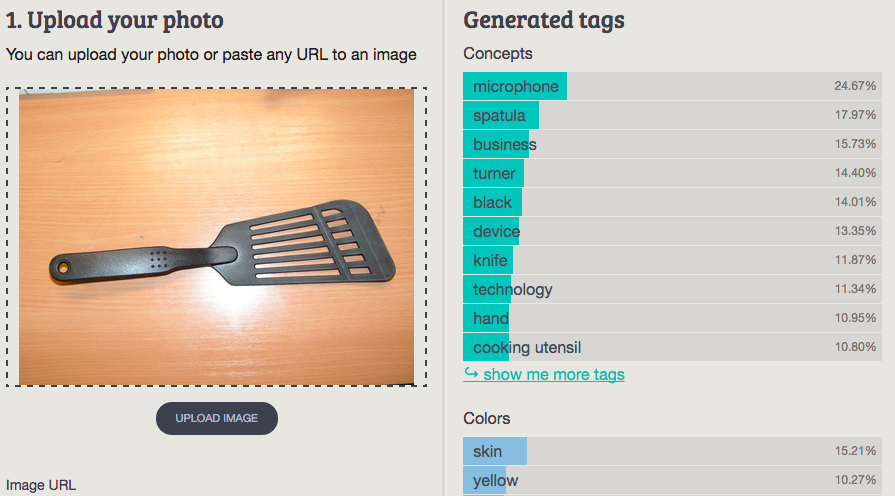
Imagga: microphone, spatula, business, turner, black, device, knife, technology, hand, cooking utensil
Wolfram ImageIdentify: spatula
CamFind: black kitchen turner
Clarifai: steel wood knife handle iron fork equipment nobody tool chrome
MetaMind: spatula
Orbeus: tool
AlchemyAPI: knife
4. Scoreboard
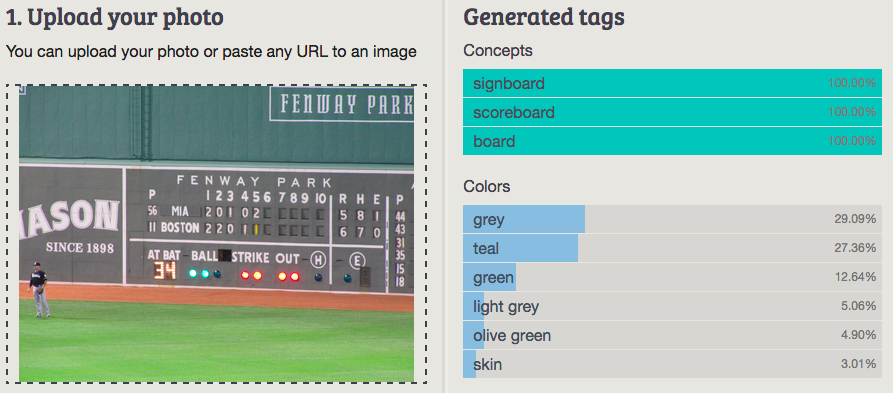
Imagga: signboard, scoreboard, board
Wolfram ImageIdentify: scoreboard
CamFind: baseball scoreboard
Clarifai: scoreboard soccer stadium football game competition goal group north america match
MetaMind: Scoreboard
Orbeus: billboard
AlchemyAPI: sport
5. German Shepherd
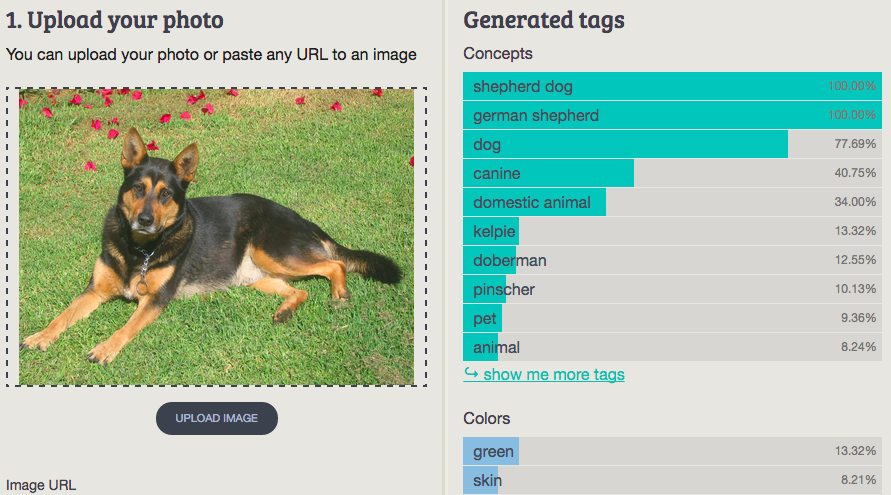
Imagga: shepherd dog, german shepherd, dog, canine, domestic animal, kelpie, doberman, pinscher, pet, animal
Wolfram ImageIdentify: German shepherd
CamFind: black and brown German shepherd
Clarifai: dog canine cute puppy mammal loyalty grass sheepdog fur German hepherd
MetaMind: German Shepherd, German Shepherd Dog, German Police Dog, Alsatian
Orbeus: animal
AlchemyAPI: dog
6. Toucan
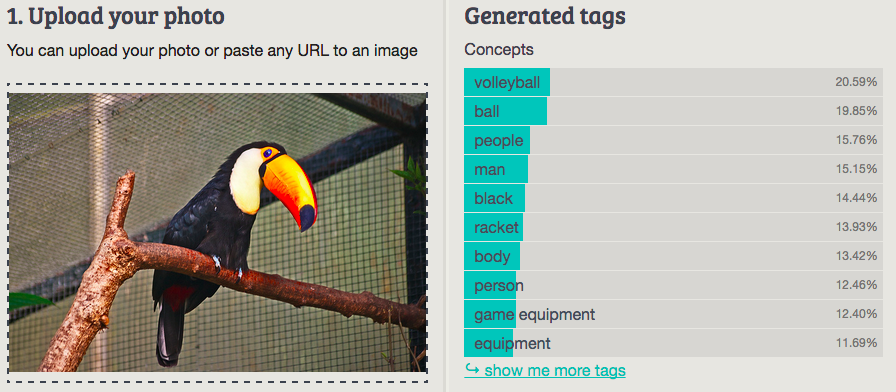
Imagga: volleyball, ball, people, man, black, racket, body, person, game equipment, equipment (nice try)
Wolfram ImageIdentify: tufted puffin
CamFind: toucan bird
Clarifai: bird one north america nobody animal people adult nature two outdoors
MetaMind: toucan
Orbeus: animal
AlchemyAPI: sport
7. Indian Cobra
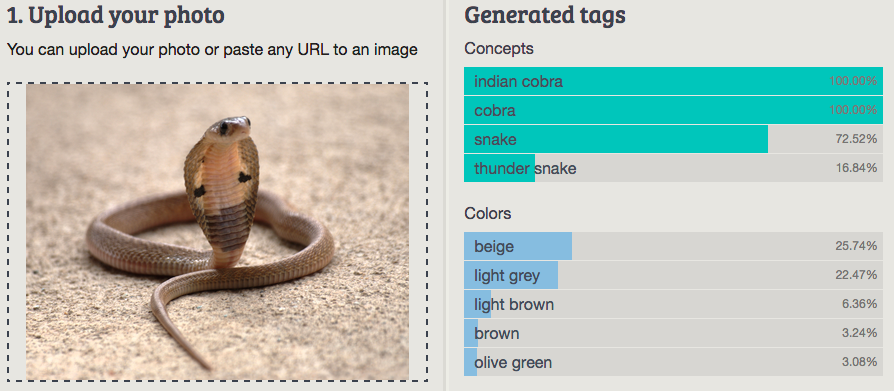
Imagga: Indian cobra, cobra, snake, thunder snake
Wolfram ImageIdentify: black-necked cobra
CamFind: brown and beige cobra snake
Clarifai: snake nobody reptile cobra wildlife daytime sand rattlesnake north america desert
MetaMind: Indian cobra, Naja Naja
Orbeus: animal
AlchemyAPI: snake
8. Strawberry
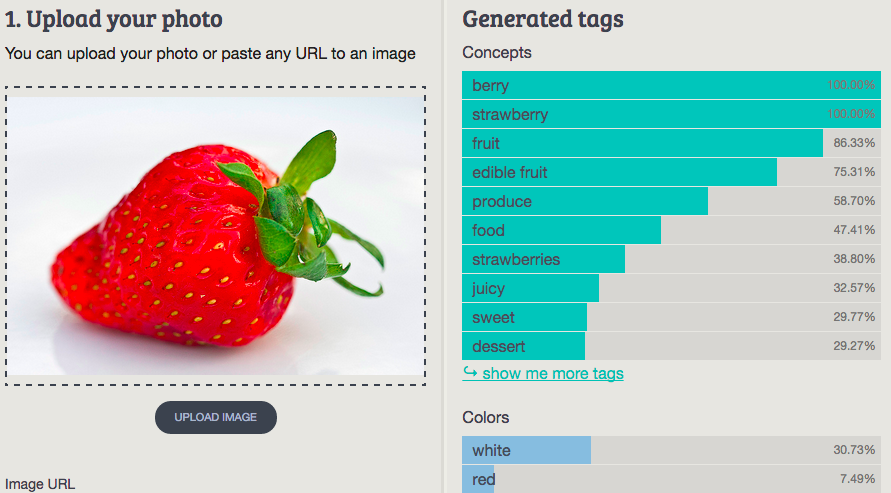
Imagga: berry, strawberry, fruit, edible fruit, produce, food, strawberries, juicy, sweet, dessert
Wolfram ImageIdentify: strawberry
CamFind: red strawberry ruit
Clarifai: fruit sweet food strawberry ripe juicy berry healthy isolated delicious
MetaMind: strawberry
Orbeus: strawberry
AlchemyAPI: berry
9. Wok
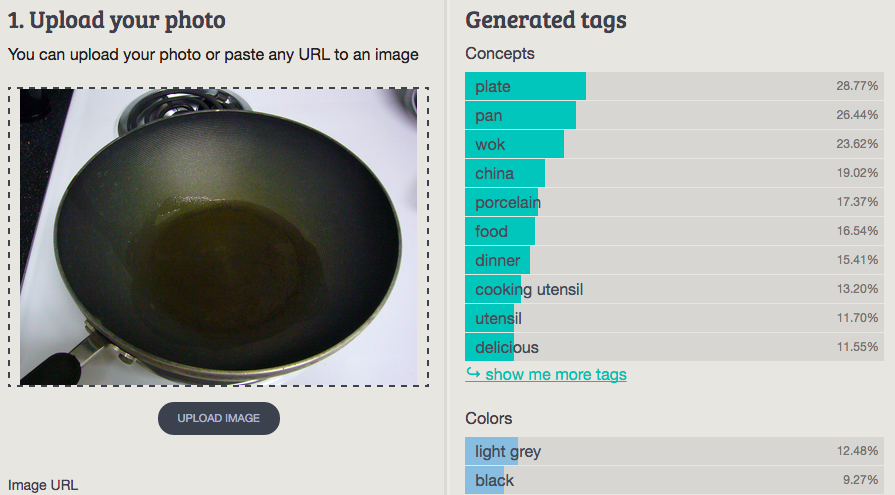
Imagga: plate, pan, wok, china, porcelain, food, dinner, cooking utensil, utensil, delicious
Wolfram ImageIdentify: cooking pan
CamFind: gray steel frying pan
Clarifai: ball nobody pan cutout kitchenware north america tableware competition bowl glass
MetaMind: wok
Orbeus: frying pan
AlchemyAPI: (No tags)
10. Shoe store
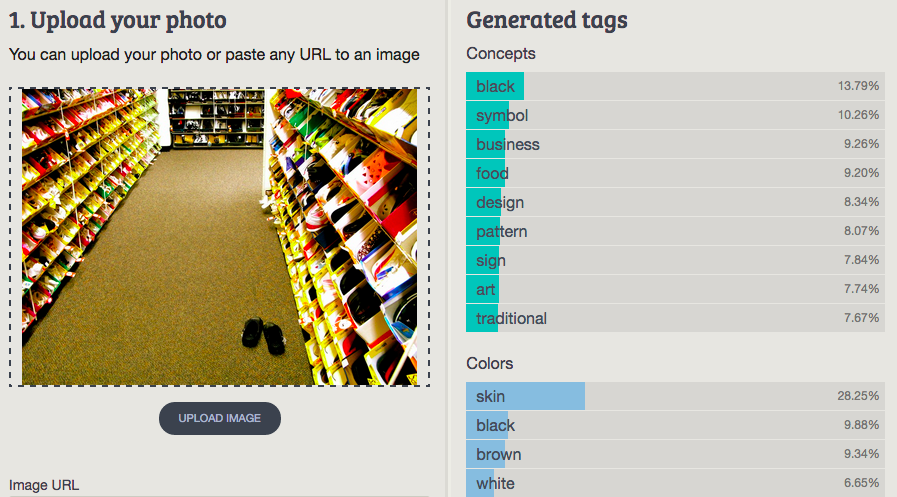
Imagga: black, symbol, business, food, design, pattern, sign, art, traditional
Wolfram ImageIdentify: store
CamFind: black crocs
Clarifai: colour street people color car mall road fair architecture hotel
MetaMind: Shoe Shop, Shoe Store
Orbeus: shoe shop
AlchemyAPI: sport
The fun part aside, we are quite interested to see soon a more comprehensive subjective and objective evaluation of all these services, including Imagga, with their pros and cons, on more representative and rich datasets, and depending on the way the tags will be used in different verticals and applications.
Competition is an important driver for every industry, so we are more than open to participate in such kinds of service comparisons and may even initiate such a comparison in the very near future.

Batch Image Processing From Local Folder Using Imagga API

This blog post is part of series on How-Tos for those of you who are not quite experienced and need a bit of help to set up and use properly our powerful image recognition APIs.
In this one we will help you to batch process (using our Tagging or Color extraction API) a whole folder of photos, that reside on your local computer. To make that possible we’ve written a short script in the programming language Python: https://bitbucket.org/snippets/imaggateam/LL6dd
Feel free to reuse or modify it. Here’s a short explanation what it does. The script requires the Python package, which you can install using this guide.
It uses requests’ HTTPBasicAuth to initialize a Basic authentication used in Imagga’s API from a given API_KEY and API_SECRET which you have to manually set in the first lines of the script.
There are three main functions in the script - upload_image, tag_image, extract_colors.
-
- upload_image(image_path) - uploads your file to our API using the content endpoint, the argument image_path is the path to the file in your local file system. The function returns the content id associated with the image.
- tag_image(image, content_id=False, verbose=False, language='en') - the function tags a given image using Imagga’s Tagging API. You can provide an image url or a content id (from upload_image) to the ‘image’ argument but you will also have to set content_id=True. By setting the verbose argument to True, the returned tags will also contain their origin (whether it is coming from machine learning recognition or from additional analysis). The last parameter is ‘language’ if you want your output tags to be translated in one of Imagga’s supported 50 (+1) languages. You can find the supported languages from here - http://docs.imagga.com/#auto-tagging
- extract_colors(image, content_id=False) - using this function you can extract colors from your image using our Color Extraction API. Just like the tag_image function, you can provide an image URL or a content id (by also setting content_id argument to True).
Script usage:
Note: You need to install the Python package requests in order to use the script. You can find installation notes here.
You have to manually set the API_KEY and API_SECRET variables found in the first lines of the script by replacing YOUR_API_KEY and YOUR_API_SECRET with your API key and secret.
Usage (in your terminal or CMD):
python tag_images.py <input_folder> <output_folder> --language=<language> --verbose=<verbose> --merged-output=<merged_output> --include-colors=<include_colors>
The script has two required - <input_folder>, <output_folder> and four optional arguments - <language>, <verbose>, <merged_output>, <include_colors>.
- <input_folder> - required, the input folder containing the images you would like to tag.
- <output_folder> - required, the output folder where the tagging JSON response will be saved.
- <language> - optional, default: en, the output tags will be translated in the given language (a list of supported languages can be found here: http://docs.imagga.com/#auto-tagging)
- <verbose> - optional, default: False, if True the output tags will contain an origin key (whether it is coming from machine learning recognition or from additional analysis)
- <include_colors> - optional, default: False, if True the output will also contain color extraction results for each image.
- <merged_output> - optional, default: False, if True the output will be merged in a JSON single file, otherwise - separate JSON files for each image.